MySql分库分表笔记
分库分表
水平拆数据,垂直拆结构
垂直拆分
垂直分库 以表为依据,根据业务将不同表拆分到不同库中。
垂直分表 以字段为依据,根据字段属性将不同字段拆分到不同表中。
水平拆分
水平分库 以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
水平分表 以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
MyCat
mysql -h 192.168.200.210 -p 8066 -u root -p 登录到MyCat
在mycat的命令行中,通过source指令导入表结构,以及对应的数据,查看数据分布情况。
source /root/shopping-table.sql 导入表
source /root/shopping-insert.sql 导入表中数据
配置文件
schema.xml 作为MyCat中最重要的配置文件之一,涵盖了MyCat的逻辑库、逻辑表、分片规则、分片节点及数据源的配置。
rule.xml中定义所有拆分表的规则,在使用过程中可以灵活的使用分片算法,或者对同一个分片算法使用不同的参数,它让分片过程可配置化。主要包含两类标签:tableRule、Function。
server.xml配置文件包含了MyCat的系统配置信息,主要有两个重要的标签:system、user。 数据库的账号密码配置文件
user -> dml='0000'增改查删IUSD
MyCat分片 垂直分库
全局表配置 schema.xml -> type=”global”
对于省、市、区/县表tb_areas_provinces, tb_areas_city, tb_areas_region, 是属于数据字典表, 在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。
MyCat分片 水平分表
逻辑表声明 schema.xml -> rule=”mod-long”
分片规则
- 范围分片
根据指定的字段及其配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。0-500w: 0 500w-1000w: 1 1000w-1500w: 2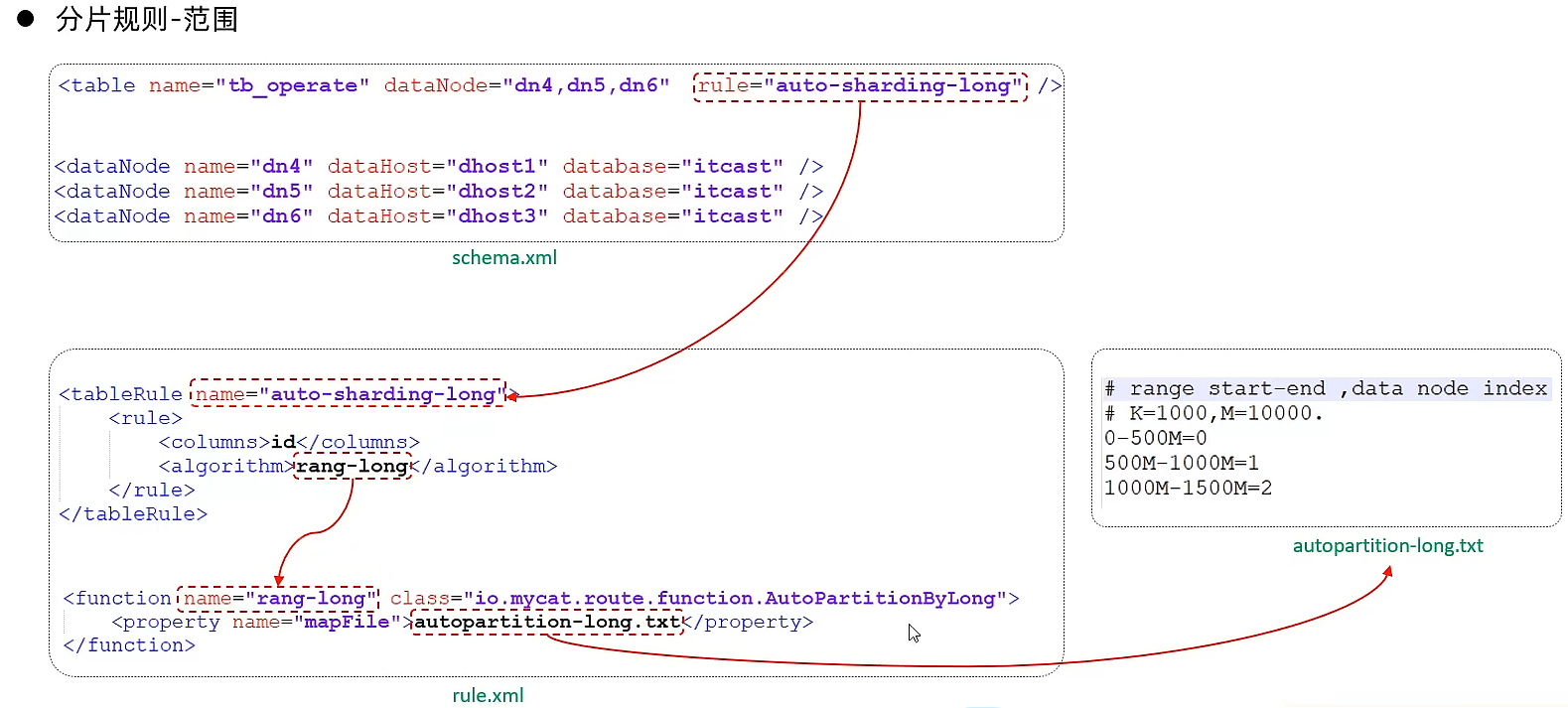
- 取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果,来决定该数据属于哪一个分片。xxx%3==0: 0 xxx%3==1: 1 xxx%3==2: 2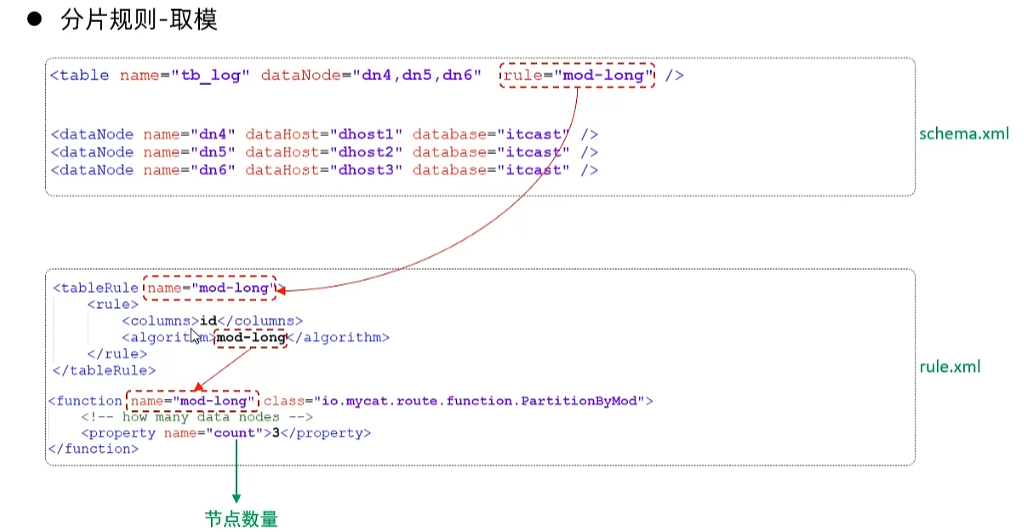
- 一致性hash 例UUID
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置。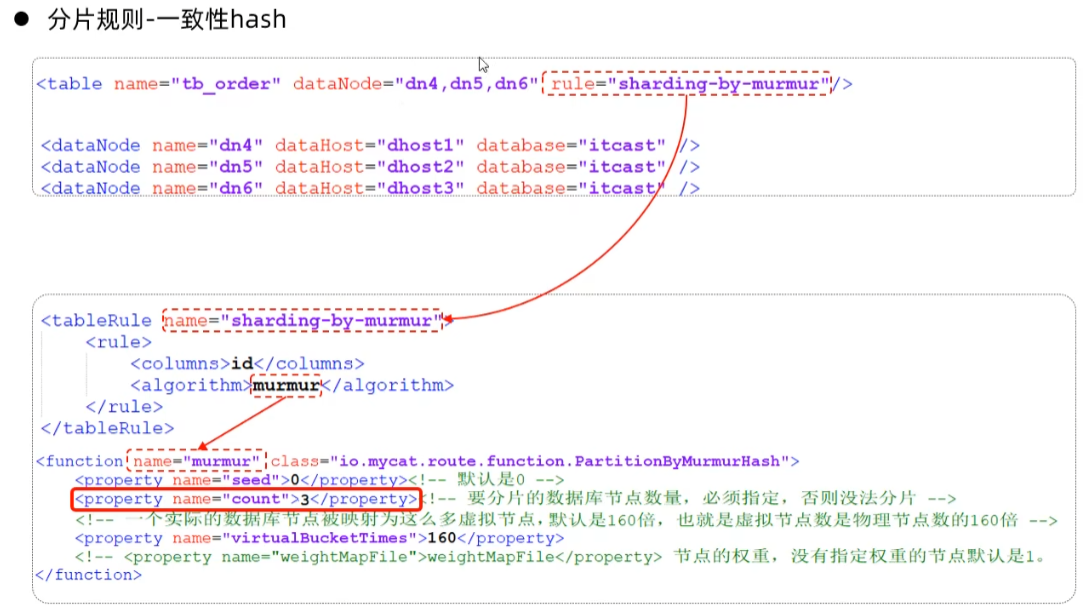
- 枚举
通过在配置文件中配置可能的枚举值,指定数据分布到不同数据节点上,本规则适用于按照省份、性别、状态拆分数据等业务。枚举值1: 0 枚举值2: 1 枚举值3: 2 <property name="defaultNodel>2</property> 插入不存在的status为4的时候不在范围内 默认到2节点
- 应用指定
运行阶段由应用自主决定路由到那个分片,直接根据字符子串(必须是数字)计算分片号。00xxxx: 0 01xxxx: 1 02xxxx: 2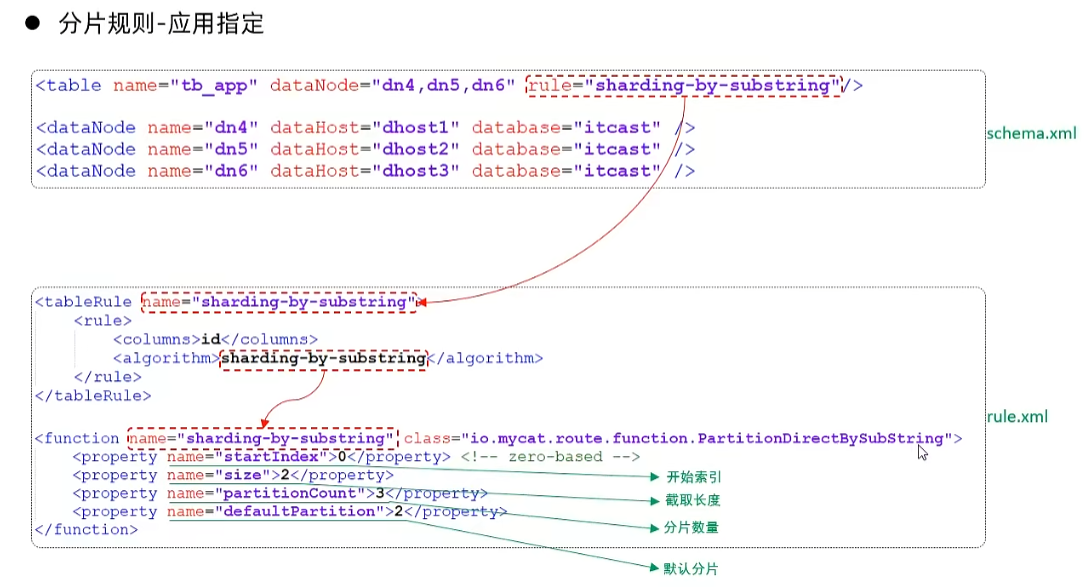
- 固定分片hash算法(结合了取模和范围的特点)
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id的二进制低10位与1111111111进行位&运算。
特点:
如果是求模,连续的值,分别分配到各个不同的分片; 但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
可以均匀分配,也可以非均匀分配。
分片字段必须为数字类型。 - 字符串hash解析
截取字符串中的指定位置的子字符串,进行hash算法,算出分片 - 按(天)日期分片
begin: 2024-01-01 end: 2024-01-30 partionday: 10 周期 每10天一个分线 2022-01-01-2022-01-10: 0 2022-01-11-2022-01-20: 1 2022-01-21-2022-01-30: 2 - 自然月
使用场景为按照月份来分片,每个自然月为一个分片。begin: 2024-01-01 end: 2024-03-31
基础规范
- 表必须有主键,建议使用整型作为主键
- 禁止使用外键,表之间的关联性和完整性通过应用层来控制
- 表在设计之初,应该考虑到大致的数据级,若表记录没有1000w,尽量使用单表,不建议分表
- 建议将大字段,访问频率低,或者不需要作为筛选条件的字段拆分到拓展表中, (做好表垂直拆分)
- 控制单实例表的总数,单个表分表数控制在1024以内。
列设计规范
- 正确区分tinyint, int, bigint的范围
- 使用varchar(20)存储手机号,不要使用整数
- 使用int存储ipv4不要使用char(15)
- 涉及金额使用decimal/varchar,并制定精度
- 不要设计为null的字段,而是用空字符,因为null需要更多的空间,并且使得索引和统计变得更复杂。
索引规范
- 唯一索引使用uniq_[字段名]来命名
- 非唯一索引使用idx_[字段名]来命名
- 不建议在频繁更新的字段上建立索引
- 非必要不要进行JOIN,如果要进行join查询,被join的字段必须类型相同,并建立索引。
- 单张表的索引数量建议控制在5个以内,索引过多,不仅会导致插入更新性能下降,还可能导致MYSQL的索引出错和性能下降
- 组合索引字段数量不建议超过5个,理解组合索引的最左匹配原则,避免重复建设索引。比如你建立了(x,y,z) 相当于你建立了(x),(x,y),(x,y,z)
SQL规范
- 禁止使用selet
*,只获取必要字段,select*会增加cpu/i0/内存、带宽的消耗。 - insert必须指定字段,禁止使用insert into Table values().指定字段插入,在表结果变更时,能保证对应应用程序无影响。
- 隐私类型转换会使索引失效,导致全表扫描。(比如:手机号码搜索时未转换成字符串)
- 禁止在where后面查询列使用函数或者表达式,导致不能命中索引,导致全表扫描
- 禁止负向查询(!=,not like ,no in等)以及%开头的模糊查询,造成不能命中索引,导致全表扫描
- 避免直接返回大结果集造成内存溢出,克采用分段和游标方式。
- 返回结果集时尽量使用limit分页显示.
- 尽量在order by/group by的列上创建索引。
- 大表扫描尽量放在镜像库上去做
- 禁止大表join查询和子查询
- 尽量避免数据库内置函数作为查询条件
- 应用程序尽量捕获SQL异常
如何平滑添加字段
场景:在开发时,有时需要给表加字段,在大数据量且分表的情况下,怎么样平滑添加。(推荐1 2 5方法)
- 直接alter table add column,数据量大时不建议,(会产生写锁)
alter table ksd_user add column api_pay_no varchar(32) not null comment '用户扩展订单号' alter table ksd_user add column api_pay_no varchar(32) not null unique comment '用户扩展订单号' - 提前预留字段(不优雅:造成空间浪费,预留多少很难控制,拓展性差)
- 新增一张表, (增加字段) ,迁移原表数据,在重新命名新表作为原表。
- 放入extinfo (无法使用索引)5:提前设计,使用key/value方法存储,新增字段时,直接加一个key就好了(优雅)